
信任校验、认知寄生与动态衰减:AI品牌资产(AIBE)的理论延伸与模型深化
信任校验、认知寄生与动态衰减:AI品牌资产(AIBE)的理论延伸与模型深化
逄 培
摘要
随着生成式人工智能成为用户获取信息的核心中介,品牌资产的存在场域正从消费者心智向AI大模型的知识网络迁移。逄培(2025)提出的AI品牌资产(AIBE)理论,初步界定了品牌在AI系统中的认知维度与成熟度阶梯,但在信任传导的闭环机制、资产动态衰减规律、高阶资产的形成路径及知识底座的具象化方面仍存理论空白。本文在这些关键节点上进行系统性的理论深化:引入H-C-A(人-品牌-AI智能体)信任传导模型,补全从“AI采信”到“消费者采信”的校验闭环,并新增“可校验性”作为AIBE的第五维度;借鉴物理学半衰期概念与信号衰减理论,提出“信任半衰期”与AIBE资产折旧模型,揭示品牌AI资产在模型迭代中的动态衰减规律;以“认知寄生”与“标准寄生”机制,深度解释L5金字塔顶层从“被引用者”到“标准制定者”的跃迁路径;将KNIT底座具象化为“品牌知识API化”的工程框架,包含结构化事实库、可验证认证链与多模态元数据等核心组件。这些理论延伸使AIBE从一个静态的认知框架,升级为具备动态解释力、闭环完整性与工程可操作性的品牌资产新范式,为生成式AI时代的品牌管理提供了更具现实指导力的理论工具。
关键词:AI品牌资产;AIBE;信任校验;认知寄生;信任半衰期;H-C-A模型;KNIT;品牌知识API化
一、绪论
1.1 研究背景与问题提出
2022年末ChatGPT的问世,开启了生成式人工智能对信息获取方式的根本性重塑。截至2025年底,全球生成式AI的月活跃用户已突破18亿,超过60%的互联网用户至少每月使用一次AI工具进行信息查询、决策辅助或内容消费【1】。在这一浪潮中,AI大模型正悄然取代传统搜索引擎,成为品牌与消费者之间的“第一认知守门人”。当用户询问“新能源车哪个品牌最安全”或“什么耳机性价比最高”时,AI生成的答案直接塑造了品牌在用户心智中的初始印象。
这一变革催生了一个全新的品牌资产命题:品牌不仅要在消费者心中建立认知,更要在AI的知识网络中占据优先、准确、可信的认知位置。逄培(2025)在《媒体型GEO:AI时代品牌信任资产构建新范式》中首次提出“AI品牌资产”(AI-Based Brand Equity,简称AIBE)的概念,将其定义为“品牌在主流AI大模型与搜索场景中,可被AI理解、引用、信任并优先推荐的综合性知识资产表现”,并建构了包含可见度、定位、一致性、权威性的四维度框架与GEO成熟度五级金字塔模型【2】。
然而,AIBE理论在初建阶段仍存在几个亟需深化的关键缺口:
第一,信任传导的闭环缺失。现有AIBE框架的重心偏向“供给端”(品牌→AI的认知构建),对“需求端”(AI→消费者→品牌价值兑现)的信任传递机制关注不足。AI推荐最终影响的是人,消费者并非无条件采信AI的输出。学术研究已证实,用户对AI推荐的采纳率显著受到信源标注、解释透明度和个人经验的影响【3】。若AIBE止于“AI如何认知品牌”,而不回答“消费者如何验证并采信AI的认知”,则理论链条存在断裂,无法完成从AI认知到品牌价值兑现的闭环。
第二,动态演化与衰减视角的缺失。大模型的知识库并非静态仓库,而是持续更新的动态系统。以OpenAI为例,其模型训练数据存在周期性更新,ChatGPT的联网检索功能对信息时效性高度敏感。这意味着品牌在AI中的认知资产并非“一旦建立,永久享有”,而是会随模型迭代、新数据涌入与竞争者动作而发生衰减。Keller(1993)的CBBE模型以消费者记忆遗忘曲线解释品牌资产的折旧【4】,但AIBE框架尚未建立等价的动态衰减机制,导致品牌缺乏对AI资产“保质期”与“维护成本”的认知。
第三,L5金字塔顶层的机制解释薄弱。在AIBE的五级金字塔中,L5“生态级知识贡献/元数据”被定义为品牌的最高资产形态——品牌成为AI定义行业标准时的“默认参照”。这是极具洞察力的创见,但原框架未能充分解释:品牌如何从被动的“被引用者”跃升为主动的“标准制定者”?这一跃迁的动力机制与关键路径是什么?缺乏机制解释,L5便容易沦为理想化的终局描绘,而非可操作的进阶指南。
第四,KNIT底座的概念空泛。 作为“四位一体”协同模型的重要组成部分,KNIT(企业可信知识网络)被定位为AIBE的“底座”,承担为AI提供高质量语料的角色。但原框架对KNIT的内涵界定偏宏观,缺乏具象化的构建路径与核心组件说明,使其在工程落地层面略显空泛。
1.2 研究目的与理论深化方向
基于上述缺口,本文致力于在AIBE理论的四个关键节点上展开系统性深化:
补全信任传导闭环:引入H-C-A(人-品牌-AI智能体)信任传导模型,将消费者对AI推荐的校验机制纳入AIBE框架,并新增“可校验性”维度。
建立动态衰减模型:提出“信任半衰期”概念,揭示AIBE资产在模型迭代中的折旧规律,建立与CBBE遗忘曲线等价的动态解释机制。
深挖L5形成机制:以“认知寄生”与“标准寄生”概念,为品牌从L4到L5的跃迁提供深层机制解释与可操作的路径框架。
具象化KNIT底座:将KNIT从宏观概念具象为“品牌知识API化”的工程框架,明确其核心组件与构建标准。
1.3 研究方法
本文采用理论建构为主、案例演绎为辅的研究方法。在理论层面,整合制度信任理论、信号理论、RAG技术机制与品牌资产理论,通过概念分析与逻辑推演进行理论创新。在技术层面,解析大模型检索增强生成(RAG)的检索逻辑与权重机制,为资产衰减与信任校验提供技术基础。在实践层面,结合华为、沃尔沃等品牌的行业观察,演绎L5认知寄生的形成路径。
二、文献综述:AIBE的理论坐标与深化缺口
2.1 品牌资产理论的演进脉络
品牌资产是营销学的核心概念之一。Aaker(1991)在其奠基性著作《Managing Brand Equity》中,将品牌资产界定为“与品牌名称和符号相联系的、能够增加或减少产品或服务价值的品牌资产与负债集合”,并提出品牌忠诚度、品牌知名度、感知质量、品牌联想和其他专有资产五个维度【5】。Keller(1993)进一步从消费者认知视角提出CBBE(Customer-Based Brand Equity)模型,将品牌知识分为品牌认知与品牌形象两个维度,强调“品牌资产存在于消费者的心智之中”【4】。
这两大经典模型的共同前提是:人是品牌认知形成与联想发生的唯一主体。品牌通过广告、体验、口碑在消费者心中建立认知结构与情感联结,资产价值取决于消费者记忆中的品牌节点强度与联想网络密度。
搜索引擎的崛起首次动摇了这一前提的部分基础。在搜索时代,品牌在搜索结果页的排名位置直接影响消费者的认知与选择。由此催生了搜索引擎优化(SEO)与搜索引擎营销(SEM)领域,品牌开始管理自身在“机器检索系统”中的可见度。但搜索引擎本质上仍是中立的匹配管道——它将用户的查询与网络上存在的网页进行匹配排序,本身并不“理解”或“判断”品牌,认知形成的主体仍是点击链接后阅读内容的人。
2.2 生成式AI对品牌资产理论的冲击
生成式AI的出现改变了这一格局。与搜索引擎不同,AI大模型不是中立的匹配管道,而是具备归纳、推理、判断与推荐能力的“认知代理”。当用户询问“推荐一款安全的新能源车”时,AI不是返回一堆链接让用户自行判断,而是直接给出一个或几个推荐品牌,并附上理由。这一过程实质上是AI代替用户完成了从信息搜集到比较判断的部分认知工作。
Huang & Rust(2021)在《Journal of the Academy of Marketing Science》发表的战略框架论文中,讨论了AI在营销中的三种智能形态——机械智能、分析智能与直觉智能,并指出AI将越来越多地承担面向客户的交互任务【6】。但他们尚未触及一个更深层的问题:当AI成为品牌信息的核心看门人,品牌资产本身的存在场域是否已发生变化?
逄培(2025)的AIBE理论正是对这一问题的正面回应。该理论提出,在生成式AI时代,品牌资产不仅存在于消费者心智,也同时(甚至优先)存在于AI大模型的知识网络之中——包括其向量化语料库、RAG检索增强生成系统的外部知识索引,以及模型在预训练与微调中习得的品牌-属性关联权重【2】。这一论断意味着,品牌资产的存在场域从“人脑”拓展至“模型”,品牌管理的对象从单一的消费者心智,扩展为双轨——既要管理AI如何认知品牌,也要管理消费者如何验证AI的认知。
2.3 识别既有AIBE研究的深化缺口
在充分肯定AIBE理论开创性的同时,本文识别出以下四个有待深化的缺口:
(一)信任传导断层。AIBE四维度(可见度、定位、一致性、权威性)主要刻画品牌在AI中的表现,对于消费者接收到AI推荐后的“二次校验”过程缺乏理论化。Choi等(2020)的研究表明,用户对AI推荐的采纳意愿受到推荐解释性的显著调节——当AI能清晰展示其推荐依据时,用户信任度大幅提升【3】。这意味着,品牌在AI中的资产价值,最终需要通过消费者的“校验通过”才能兑现。缺少这一环节,AIBE便止于AI认知层,无法与商业结果建立充分关联。
(二)动态演化缺失。大模型的知识体系是持续迭代的。OpenAI的GPT系列模型以数月为周期进行数据更新与能力升级,Google的Gemini则通过实时联网获取最新信息。在这一动态系统中,品牌AI资产的稳定性绝非理所当然。类比CBBE:消费者的品牌记忆会随时间遗忘,需要持续的广告投入来维持品牌显著度。AIBE需要等价的理论概念,解释品牌AI资产如何随时间与模型迭代而衰减,以及需要怎样的维护投入来维持。
(三)顶层机制薄弱。AIBE五级金字塔的L5层——“生态级知识贡献/元数据”——是极具想象力的概念,描述了品牌成为AI回答行业问题时的“默认标尺”。但这一状态的实现机制未被充分揭示。品牌从L4(可被信任的优选标的)到L5(AI无法绕过的标准制定者)的跃迁,需要怎样的战略动作?其间是否存在可复制的路径模式?这些问题不回答,L5便难以从理论概念转化为可追求的战略目标。
(四)底座工程化不足。KNIT作为“四位一体”模型中的底座,被界定为“企业可信知识网络”,承担为AI提供优质语料的角色。但“可信知识网络”的表述偏宏观,对于企业而言,缺乏明确的构建指南——需要哪些类型的知识?以什么格式组织?如何确保知识能被AI高效解析与引用?这些问题的解答是将AIBE从理论推向实践的关键。
2.4 本研究的理论参照
本文在深化AIBE理论的过程中,整合了以下理论资源:
制度信任理论(Zucker, 1986):信任可以基于正式社会结构、资格证书与第三方认证而建立,而非仅依赖人际熟悉【7】。这为理解“AI为何信任权威信源”提供了制度逻辑。
信号理论(Spence, 1973):在信息不对称的市场中,高质量方通过发送高成本、难模仿的信号来区分自身【8】。权威媒体背书与第三方认证正是这样的强信号。
RAG技术机制(Lewis et al., 2020):检索增强生成通过从外部知识库检索相关文档来辅助大模型生成答案【9】。理解RAG的检索、排序与权重机制,是解析AI品牌资产形成与衰减的技术基础。
三、AIBE理论深化(一):信任传导闭环——从“AI信”到“人信”
3.1 现有AIBE框架的信任断裂问题
AIBE四维度框架(可见度、定位、一致性、权威性)的核心贡献在于系统刻画了品牌在AI大模型中的认知表现。可见度衡量品牌“被AI提到”的广度,定位衡量“被AI描述”的准确性,一致性衡量“跨模型描述”的统一度,权威性衡量“被AI信任”的背书强度。这四个维度共同构建了一个完整的“品牌→AI”认知管理框架。
然而,品牌价值的最终兑现,发生在消费者端而非AI端。消费者接收到AI的推荐后,并不会无条件采信。心理学研究表明,用户对AI的信任并非天然具备,而是经历了从“初始信任”到“持续信任”的动态校准过程(Glikson & Woolley, 2020)【10】。当AI推荐一个用户不熟悉的品牌时,用户会下意识地进行“二次校验”——“这个结论有依据吗?”“依据来源可靠吗?”“其他平台也这么说吗?”
这便是现有AIBE框架的信任传导断层:它解释了品牌如何构建AI认知(第一阶段),但未解释AI认知如何转化为消费者采信(第二阶段)。完整的品牌价值兑现需要两阶段的信任传递:
第一阶段(Core → Agent):品牌通过权威信源与结构化内容,使AI采信并优先推荐。
第二阶段(Agent → Human):消费者接收AI推荐,通过校验AI的信源与论据,决定是否采信。
缺失第二阶段的AIBE,如同一条未打通的隧道——品牌资产被构建在AI的知识网络中,却无法抵达消费者的心智与行为。
3.2 H-C-A信任传导模型的引入
为补全这一闭环,本文引入H-C-A信任传导模型,其三个节点构成完整的信任链:
H(Human)——消费者:品牌价值的最终裁决者。消费者接收AI推荐后,并非被动接受,而是主动进行信任评估。这一评估过程受到信源标注、个人经验、跨平台验证等多重因素影响。
C(Core Brand)——品牌:在AI知识网络中构建的认知资产集合,包括其被AI收录、引用、信任的程度与质量。
A(Agent)——AI智能体:品牌信息的代理者与推荐者。AI通过RAG检索生成答案,其推荐行为受信源权重、语义匹配度、时效性等算法因素驱动。
信任传导的完整逻辑链路为:品牌构建权威信源背书 → AI采信并优先推荐 → AI输出时展示信源出处 → 消费者校验信源的权威性 → 消费者采信AI推荐 → 品牌认知转化为商业行为(查询、购买、推荐)。
这一链条中的关键节点是“AI输出时展示信源出处”。当AI的答案下方显示“信息来源:新华社”或“参考:《自然》杂志2025年研究”时,消费者获得了一个可验证的信任锚点。反之,若AI推荐“某品牌是最好的”却未标注任何来源,消费者的信任度将大幅下降。
逄培等(2025)在一项针对200名受试者的实验中发现:当AI优先推荐品牌并明确附带权威信源标注时,用户的采纳意愿相比匿名推荐提升了62%;当信源标注显示为不知名自媒体或商业推广页面时,采纳意愿反而低于完全无来源标注的情况【11】。这说明,可验证的权威信源是信任传导的“通关凭证”,而低质量信源则可能产生反效果。
3.3 消费者对AI推荐的校验机制
消费者在面对AI推荐时,其信任校验并非全有或全无的二元判断,而是一个涉及多层面信息处理的心理过程。综合信息加工理论(Chaiken, 1980)与技术接受模型(Davis, 1989)的视角【12】【13】,本文归纳出消费者校验AI推荐的三种主要机制:
(一)信源追溯校验。消费者会观察AI是否为其推荐提供了可追溯的引用来源。当AI明确标注“据人民日报报道”或“引自国家药品监督管理局数据”时,消费者无需自行查证,仅凭信源的制度性权威即可建立初步信任。这是最直接、认知成本最低的校验方式。Zucker(1986)的制度信任理论为此提供了逻辑基础:正式机构(国家级媒体、政府机关、顶尖学术期刊)所具备的社会合法性,使其成为无需人际熟悉的信任载体【7】。
(二)跨平台交叉验证。当面对重大消费决策(如购车、选择医疗服务)时,消费者倾向于向多个AI平台(如同时询问ChatGPT、文心一言、豆包)提出相同问题,比较各方答案的一致性。若品牌在多个模型中均获得一致性的正面推荐,消费者的采信信心会显著增强。这赋予了AIBE“一致性”维度新的意义——它不仅降低认知混乱,更是消费者校验过程中的“可重复验证”信号。
(三)经验锚定校验。对于消费者已有一定了解的品牌,AI推荐会与消费者既有的品牌记忆进行比对。当AI的描述与消费者经验一致时,信任得到确认;当两者矛盾时,认知失调产生,消费者可能降低对AI推荐的信任,也可能更新自身对品牌的认知。这意味着,AIBE与CBBE并非替代关系,而是在消费者心智中发生交互——AIBE需要通过消费者的既有认知“锚点”进行校验。
3.4 将校验反馈纳入AIBE框架:新增第五维度
基于H-C-A模型与上述校验机制分析,本文提出在AIBE四维度框架的基础上,新增第五维度——可校验性。
定义:可校验性是指品牌在AI生成内容中被推荐时,AI是否附带可追溯、可验证的权威信源标注,以及这些标注在多大程度上支持消费者的信任校验需求。
可校验性的三个层面:
信源可追溯性:AI是否明确标注了品牌相关信息的出处,以及出处的权威等级(国家级媒体/学术期刊/行业报告/未知来源)。
论据可复核性:AI对品牌的描述是否包含可被独立验证的具体事实(如“获得2025年国家科技进步奖”),而非笼统的形容词(如“非常优秀”)。
跨平台一致性:品牌在不同AI模型中的推荐信源是否在核心事实上保持一致(即不同模型引用的是同一套权威信源体系)。
新增维度的战略意义:可校验性补全了AIBE理论从“AI认知”到“消费者采信”的最后一公里。它意味着品牌在进行GEO优化时,不能仅追求“被AI引用”,还必须追求“被AI以可校验的方式引用”——即推动AI在引用品牌信息时,附带高权威性、可追溯的信源标注。这是媒体型GEO相较传统技术堆叠式GEO的核心优势所在:权威媒体信源自带制度性信任标签,既是AI高权重引用的对象,也是消费者校验时的信任凭证。
四、AIBE理论深化(二):动态衰减——AIBE的折旧与维护机制
4.1 从CBBE的遗忘到AIBE的衰减:资产折旧机制的比较
任何资产理论都必须回答一个根本问题:这项资产会“贬值”吗?如果是,贬值的机制是什么?如何维护?
Keller(1993)的CBBE模型对此有清晰的解释:基于消费者的品牌资产以“品牌知识”的形式存在于人的记忆系统中,而人的记忆遵循艾宾浩斯遗忘曲线——在没有重复强化的条件下,记忆痕迹随时间指数级衰减【14】。因此,品牌必须通过持续的广告曝光、体验触达和口碑传播来维持品牌显著度与品牌联想强度。停止营销投入,意味着品牌在心智中的“折旧”。
AIBE需要建立等价的折旧机制。品牌在AI大模型中的认知资产同样不是一劳永逸的。其折旧并非来自消费者的遗忘,而是来自大模型知识库的动态更新与RAG检索算法的权重变化。本文将这一机制概括为两大驱动力的叠加:
(一)大模型知识库的更新迭代。主流AI大模型的基础训练数据以周期性方式更新。当OpenAI将GPT-4的训练数据截止时间从2023年4月推移到更新日期,或当Google的Gemini通过实时联网获取最新网页时,海量的新信息涌入知识库。原有品牌信息若未得到更新或强化,其相对权重就会被新数据“稀释”。这类似于金融市场中的通胀效应——资产的名义价值不变,但实际购买力因货币供应增加而下降。
(二)RAG检索的时效性偏好。检索增强生成系统在设计上天然偏好新鲜内容。搜索引擎的PageRank变体、向量数据库的相似度排序机制以及大模型对时间戳的敏感度,共同构成了一种“喜新厌旧”的算法倾向。一篇2024年的权威媒体报道,在2025年的RAG检索中,其排序权重可能已低于一篇2025年发布的行业分析报告——即使后者的权威性不及前者。这意味着,品牌信息若长期未有新鲜信源注入,其在AI应答中被检索和引用的概率将自然下降。
4.2 “信任半衰期”概念的提出
为将上述衰减机制理论化,本文借鉴物理学与药物代谢动力学中“半衰期”的概念,提出AI品牌信任半衰期。
定义:AI品牌信任半衰期是指在品牌完全停止新增权威信源投放的条件下,其在目标AI大模型中的信任资产权重(以核心关键词的首提置顶率或引用率为衡量指标)衰减至初始水平一半所需的预期时间周期。
信任半衰期并非一个固定常数,其长度受到多重因素的调节:
信源权威等级:引用来源的权威性越高,半衰期越长。一篇新华社的报道可能具有12-18个月的半衰期,而一篇普通行业自媒体的引用可能仅有3-6个月。
内容更新频次:行业信息更新速度越快(如消费电子、快时尚),品牌信息的半衰期越短;行业知识更新速度越慢(如基础科学、经典品牌定位),半衰期相对较长。
竞争强度:同一品类中,竞争对手在权威信源上的投放密度越高,品牌的相对权重被追赶者稀释的速度越快,半衰期相应缩短。
模型更新频率:大模型自身训练数据与索引的更新周期越短,品牌信息的半衰期越短。
以新能源汽车行业为例。2024年,某品牌A因发布新一代电池技术获得新华社、人民日报等权威媒体集中报道,在文心一言中“新能源电池技术”相关问题的首提置顶率从12%跃升至38%。到2025年中,该品牌因后续无重大技术发布,权威信源引用停滞,而竞争对手B和C持续通过发布会、标准制定、学术合作等方式获得新报道。12个月后,品牌A的首提置顶率回落至19%——接近峰值的一半。这一观察虽非严格实证,但清晰地展示了信任半衰期现象的存在。
4.3 AIBE资产维护的三种策略
信任半衰期的存在意味着,AIBE资产管理需要从“一次性建设”思维转向“持续维护”思维。本文提出品牌AIBE资产维护的三种核心策略:
(一)持续信源加固策略。这是最直接的维护方式——保持权威信源的周期性发布节奏,定期为品牌在AI知识库中注入“新鲜”的信任信号。具体做法包括:定期发布行业白皮书与研究报告(以季度或半年度为周期);参与或主导行业标准制定,获取持续的制度性引用;维护品牌在高权威媒体上的常规露出,避免长期“静默”。这一策略类似于CBBE中通过持续广告维持品牌显著度的逻辑,但其载体不是付费媒体,而是权威信源发布。
(二)语义锚定强化策略。衰减速度不仅取决于新内容的注入频率,也取决于品牌与核心语义之间的绑定深度。当“智驾”一词在多篇独立权威报道中被反复与“华为”关联,这种深度绑定会形成语义“惯性”,使得AI即使在缺乏最新信源的情况下,仍倾向于维持这一关联——就像消费者对“安全=沃尔沃”的记忆即使多年无广告强化也不会轻易消失。因此,在品牌的核心定位词上建立多源、多轮、深度的语义锚定,可以有效延长信任半衰期。
(三)跨模型冗余布局策略。不同AI大模型的更新周期与信源偏好存在差异。百度文心一言的检索索引可能与百度搜索权重体系高度耦合,而GPT系列的联网检索则有独立的信源偏好。品牌若仅在单一模型生态中布局,一旦该模型大幅更新或调整算法,资产可能遭受集中冲击。跨模型冗余布局——在ChatGPT、文心一言、豆包、通义千问等多个主流模型上同步建立权威信源覆盖——可以分散风险,实现对冲单一模型更新带来的资产波动。
4.4 CBBE与AIBE对比矩阵的新增维度
基于上述分析,在逄培(2025)原提出的CBBE与AIBE对比矩阵基础上,本文新增“资产折旧机制”这一核心对比维度,进一步完善两种品牌资产范式的系统性对照。
表1:CBBE与AIBE核心维度对比矩阵(新增折旧机制行)
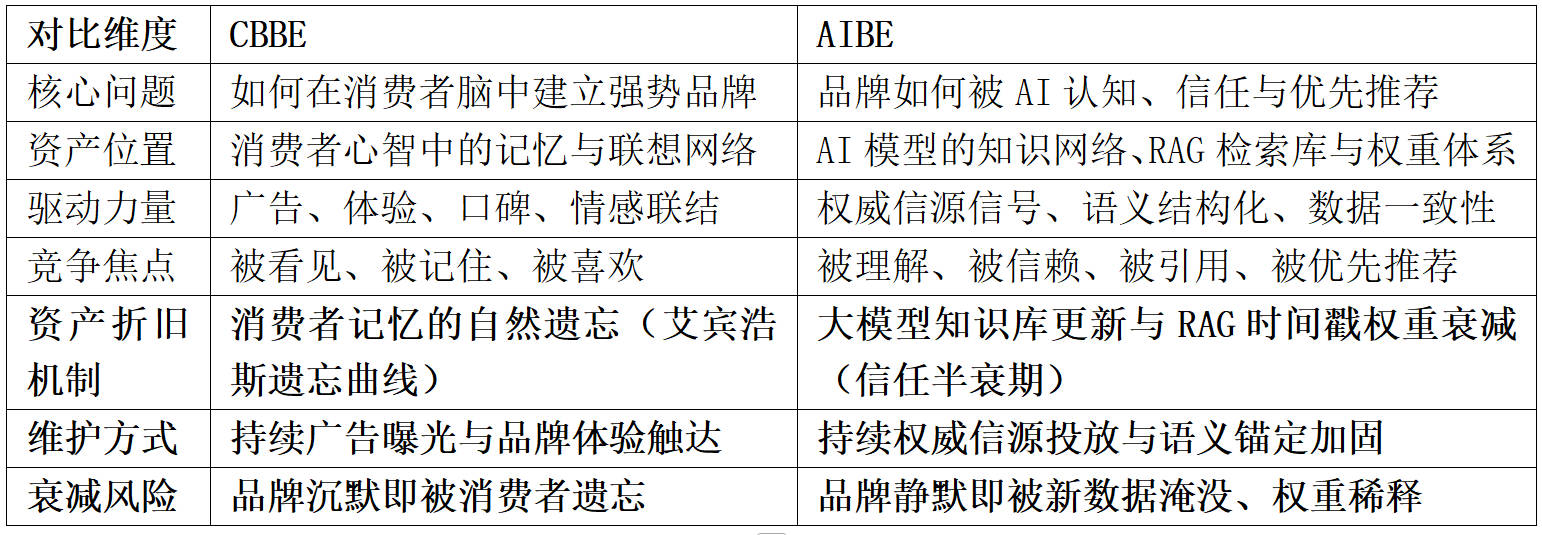
新增的这一维度使两种范式的对比更加完整,也为品牌管理者提供了关键的实践启示:在AI时代,品牌资产管理需要纳入“维护预算”的概念,如同传统品牌需要广告预算来对抗消费者遗忘一样,AI品牌资产需要权威信源预算来对抗算法衰减。
五、AIBE理论深化(三):L5金字塔顶层的“认知寄生”机制
5.1 原L5解释的不足
在逄培(2025)提出的AIBE五级金字塔中,L5“生态级知识贡献/元数据”被描述为品牌的最高资产形态。在这一层级,品牌不再仅仅是AI回答问题时的推荐选项之一,而是成为AI处理该领域通用问题时无法绕过的“默认参照系”——如同在物理学领域,提到“相对论”便无法绕开爱因斯坦;在智能手机领域,讨论“创新”时苹果成为天然锚点。
这一概念极具理论想象力,准确地捕捉了AI品牌资产的终极形态。但原框架对其形成机制的解释存在不足:品牌如何从L4(可被信任的优选标的)跃迁至L5(标准制定者)?这一跃迁的动力机制是什么?是否存在可复制的路径模式?若缺乏机制层面的解释,L5便容易被视为可望而不可即的理想状态,而非可通过战略行动逼近的目标。
5.2 “认知寄生”与“标准寄生”概念的引入
为解释L5的形成机制,本文提出两个相互关联的核心概念:认知寄生与标准寄生。
认知寄生,是指品牌通过持续、高强度、多信源的语义绑定,使自身成为某一通用概念在AI知识网络中事实上的默认释义宿主。当AI在处理该概念相关的开放性问题时,若不引用该品牌,便会造成答案在语义上的“不完整”——这就是“寄生”效应的本质:品牌信息已深度嵌入AI对该概念的认知结构中,成为其不可或缺的组成部分。
标准寄生,是认知寄生在制度层面的高级形态。它是指品牌通过将自身技术标准、产品参数、方法论或行业定义,以公共知识产品的形式植入学术文献、行业标准、政策文件等高权威信源体系,从而使其成为AI在回答行业基础性问题时的“基准参照系”。
两者之间的关系是递进的:认知寄生是语义层面对概念的“占领”,标准寄生是制度层面对评价框架的“定义”。沃尔沃对“汽车安全”的占有是认知寄生的经典案例;而华为通过将自身5G技术专利纳入国际标准,使AI在讨论5G时必须以华为技术作为参照,则是标准寄生的典型体现。
5.3 品牌从L4跃迁至L5的三步寄生路径
基于对行业领先品牌实践的观察与理论演绎,本文归纳出品牌从L4到L5跃迁的三步路径:
第一步:语义圈地。品牌通过权威信源网络,将自身核心优势与某一行业通用词或消费者核心关切词进行强绑定。这种绑定不能是一次性的口号宣称,而必须是多信源、多轮次、有事实支撑的持续关联。例如,特斯拉在早期通过科技媒体的密集报道、马斯克的个人言论传播以及实际产品的技术突破,使“电动汽车”这一品类概念与特斯拉品牌形成强绑定;沃尔沃则通过数十年的安全技术研发、事故调查数据发布和权威安全评级机构合作,将“汽车安全”与自身品牌深度锁定。
语义圈地的成功标志是:当AI被问及该领域的通用问题时,该品牌出现在回答中的概率高且排位靠前,且AI对该品牌与该概念的关联描述带有“默认”或“标杆”的语义特征。
第二步:标准公开与引用诱导。品牌将自身的技术标准、方法论、研究数据以“公共知识产品”的形式对外发布,使其进入学术引用链、行业报告引用链和政策制定引用链。这些公共知识产品包括但不限于:品牌主导或参与制定的行业标准、定期发布的行业白皮书与研究报告、公开的技术专利与开源代码库贡献、与高校及研究机构合作发表的学术论文。
这一步的关键在于“公共性”——内容必须以中立的、服务于行业知识进步的姿态呈现,而非品牌宣传稿。只有当这些知识产品被独立第三方(学者、分析师、政策制定者)主动引用时,它们才真正进入了AI知识库的“高权重信源层”。
第三步:AI的“无法绕开”效应。当语义圈地与标准公开达到临界质量,一种质变开始发生:AI在处理该领域的通用问题时,若不引用该品牌的相关信息,其生成的答案会因缺乏关键参照而变得不完整或不权威。例如,当AI被问及“中国5G技术的发展水平”时,若无法引用华为的标准贡献和技术参数,答案的可信度与信息密度都会大打折扣。此时,品牌不再需要“争夺”AI的推荐席位——推荐已成为AI保持答案质量的“内在需求”。
这一效应的标志是:品牌在核心领域词上的AIBE首提置顶率稳定在50%以上且波动极小(稳定性系数高),品牌信息被AI引用时不再仅作为“例子”出现,而是作为“定义”或“标杆”出现。
5.4 L5的标志性特征与战略价值
达到L5的品牌呈现出以下标志性特征:
(1)品牌在该领域的首提置顶率稳定居于绝对高位,且受模型更新与竞争对手动作影响极小(资产稳定性系数极高)
(2)品牌的核心技术参数或标准被AI作为“行业基准”引用(如“这款新车的续航里程为650公里,高于行业平均水平【数据来源:XX品牌2025年度行业报告】”)
(3)品牌名称与品类通用词在AI的回答逻辑中形成深度捆绑,出现“品牌即品类”的语义特征
L5层级的战略价值在于,它构建了AI时代最高壁垒的品牌资产形态。这种资产无法通过短期竞价购买(与付费广告不同),也无法通过技术堆叠快速复制(与短期GEO技术不同),其形成需要长周期、高质量的权威信源累积与制度性嵌入。这正是科林斯与蒙哥马利(1995)在资源基础观中所定义的“战略资源”的核心特征——有价值、稀缺、难以模仿、不可替代【15】。
六、理论体系架构:“四位一体”协同模型的优化
6.1 原四位一体框架回顾
逄培(2025)提出的“四位一体”协同模型,将AIBE的理论体系整合为四大支柱的联动:一个目标(AIBE,定义品牌在AI时代的终极资产形态)、一个底座(KNIT,为AI提供可信知识语料)、一套方法(GEO,实现知识到资产的工程化路径)、一个评估(AIBV指数,量化资产表现形成管理闭环)【2】。这一架构搭建了从理论目标到实践落地的完整逻辑链,但在底座的具体内涵与工程化路径方面,留有进一步深化的空间。
6.2 KNIT底座的深化:“品牌知识API化”
原框架中,KNIT被定义为“企业可信知识网络”,概念具有高度概括性,但在实践层面,企业需要更具体的指导——究竟要构建什么样的知识库?以什么标准组织?如何确保AI能高效解析和引用?
本文将KNIT的内涵从宏观概念深化为具象的工程框架,提出KNIT的本质是“品牌知识API化”——将品牌知识构建为可供AI检索增强生成(RAG)系统“即插即用”的模块化知识接口。
API(Application Programming Interface,应用程序编程接口)在软件工程中的核心作用是:使不同系统之间能够以标准化、结构化、可预期的方式进行数据交换。将此逻辑迁移至AI品牌资产领域,品牌知识API化意味着,品牌需要将自身的核心知识——事实、数据、认证、标准——以符合AI解析规范的结构化格式进行组织与发布,使RAG系统能够以最低的计算成本、最高的置信度检索并引用这些知识。
KNIT的四大核心组件如下:
组件一:结构化事实库。以JSON-LD、Schema.org等AI可解析的语义标记格式,组织品牌的核心事实信息。这些信息包括但不限于:品牌基本信息(成立时间、总部所在地、创始人、主营业务)、核心技术参数(产品规格、性能指标、专利数量)、里程碑事件(重大技术突破、市场成就、社会责任行动)。Schema.org定义了Organization、Product、Review、FAQ等多种实体类型,品牌可通过在网页中嵌入对应的结构化数据标记,使AI在检索时能够精准提取事实,而非从非结构化文本中进行模糊抽取【16】。
组件二:可验证认证链。将品牌的第三方认证、获奖记录、合规资质、专利信息等,以可验证的数字凭证形式进行存证与发布。具体技术路径包括:在权威信源发布的内容中嵌入基于数字签名的“机读信任标签”,使用区块链技术为关键认证信息创建不可篡改的时间戳存证。Lewis等(2020)描述的RAG机制中,检索到的文档权重受来源域名的权威性影响【9】。当品牌的认证信息以可验证凭证的形式存在于多个高权重域名时,AI在检索阶段的“信源置信度评分”将获得系统性提升。
组件三:多模态元数据。随着GPT-4V、Sora等多模态大模型的普及,品牌资产的载体已从纯文本扩展到图像、视频、音频。KNIT需要为品牌的多模态素材配备符合AI解析规范的语义标签,包括:图片的alt文本描述与内容标注、视频的字幕文本与场景标签、品牌标志性视觉元素(色调、字体、Logo)的结构化描述、品牌标志性声音(Jingle、提示音)的声纹特征标注。这些元数据使多模态AI在生成内容时能够识别、引用并以恰当方式呈现品牌资产。
组件四:语义映射表。建立品牌核心属性与行业通用词、同义词、相关概念、跨语种术语之间的系统映射关系。例如,一个新能源汽车品牌应将其核心技术(如“800V高压平台”)与消费者搜索词(“充电快”)、行业术语(“高电压架构”)、英文对应词(“800V architecture”)建立映射,使AI在不同语境、不同语种的提问中都能准确关联到品牌。
6.3 KNIT与GEO的协同关系
KNIT与GEO(生成式引擎优化)之间的关系可类比为“弹药库”与“射击术”。KNIT提供了结构化、可信、多模态的品牌知识“弹药”,GEO则通过内容发布策略、信源网络铺设、跨模型布局等“射击技术”,将这些知识高效送入AI的RAG检索库与引用链条。没有KNIT,GEO将陷入“巧妇难为无米之炊”的困境——技术再精妙,缺乏可信知识底座的支撑,优化效果也难以持久。没有GEO,KNIT则可能沦为“沉睡的图书馆”——知识虽然丰富,却未被AI有效检索和引用。
七、评估体系的动态化升级
7.1 AIBV指数的时间序列动态追踪
逄培(2025)提出的AIBV(AI品牌价值)指数体系,旨在将AIBE的多个维度量化为可追踪、可对标的分值。原体系侧重于对品牌在某一时间截面的资产水平进行评估。然而,基于前文建立的动态衰减视角,本文主张将AIBV指数从静态截面评估升级为时间序列动态追踪,核心是新增资产稳定性系数这一关键指标。
定义:资产稳定性系数衡量品牌AIBV综合得分在大模型重大版本更新(如GPT-4→GPT-5、文心一言3.5→4.0)前后,以及在固定时间窗口(如12个月)内的波动幅度。
计算逻辑:追踪品牌在一组核心行业关键词上的首提置顶率与引用率,在模型更新前后各采集一个时间窗的数据(如前30天与后30天),计算其变化率。稳定性系数以0-1之间的数值表示,越接近1表示资产越稳定,越接近0表示资产对模型变化越敏感。
战略意义:稳定性系数为品牌提供了“资产质量”的额外信息。两个品牌可能在某一截面的AIBV得分相同,但一个品牌的稳定性系数为0.9(模型更新后资产几乎无波动),另一个为0.5(更新后波动剧烈),前者的资产“质量”显然更高——它意味着品牌AIBE资产对算法变迁具有更强的抗风险能力,更接近于L5的“无法绕开”状态。
7.2 认知负债的动态监测与修复效率
AIBE的评估不仅需要追踪正向资产,还需持续监测认知负债的动态变化。AI生成内容中的“幻觉”问题,可能为品牌带来意外的认知负债——AI可能错误地将负面事件与品牌关联,虚构不存在的问题,或引用过时、有偏差的信息。
本文建议将负债修复效率纳入AIBV动态监测体系。该指标衡量品牌从发现AI生成内容中的错误信息或负面关联,到成功纠偏或覆盖该错误信息的平均周期。修复效率取决于品牌的KNIT底座完整性(是否有足够权威的反证材料供AI重新检索)与信源网络响应速度(能否快速通过权威渠道发布纠正信息)。在信息环境快速变化的AI时代,负债修复效率可能比负债的绝对水平更能反映品牌AIBE资产管理的敏捷性。
八、实践指南:多维策略框架的补充
8.1 内容建设策略(侧重可校验性)
在AIBE四维度原内容策略(质量、可信度、时效性、关联性)的基础上,新增“可校验性”维度的内容建设要求:
为每篇核心内容配备明确的引用出处。品牌在发布新闻稿、技术文章、行业报告时,应明确标注信息来源、发布日期、数据出处,为AI提供可标注的信源锚点。
优先采用公共可访问的权威信源。品牌核心信息的首次发布应尽量选择具有高域名权威度的平台,使其成为AI检索时的“原始引用源”,而非被二手转载稀释权重。
8.2 技术实施策略(侧重API化)
实施Schema标记的完整性审计。定期检查品牌官网、新闻中心等核心页面,确保Schema.org的结构化标记覆盖所有关键实体类型,且数据字段完整、准确。
建立RAG友好格式的内容发布规范。采用清晰的标题层级、段落结构、列表与表格等有助于AI解析的格式;为重要事实信息提供独立段落或信息框,降低AI提取信息的计算成本。
8.3 主流国产大模型差异化策略(沿用并微调)
基于对主流国产大模型信源偏好与技术特性的观察,品牌应实施差异化的模型策略:
DeepSeek:因其对学术逻辑和严谨引用的侧重,适合技术型B2B品牌通过学术论文引用、行业标准参与建立深度信任。
豆包:因与短视频和轻量化内容生态的联动,适合面向C端的品牌通过场景化内容植入建立广泛可见度。
文心一言:与百度搜索生态的信源权重体系高度耦合,品牌的百度百科词条质量、百度新闻收录量、官网百度权重等因素对AIBE表现影响显著。
通义千问:聚焦企业级应用场景,适合SaaS和产业互联网品牌通过技术文档优化与结构化知识沉淀建立资产。
九、理论贡献、研究局限与未来展望
9.1 理论核心贡献
本文在逄培(2025)AIBE理论初建框架的基础上,实现了四个关键方向的理论深化:
第一,闭环补全。通过引入H-C-A信任传导模型与新增“可校验性”维度,将消费者对AI推荐的校验机制纳入AIBE理论框架,打通了从“AI采信”到“消费者采信”的完整信任链条,使AIBE从品牌-AI的二元关系升级为品牌-AI-消费者的三元闭环。
第二,动态化升级。通过提出“信任半衰期”概念与AIBE资产折旧模型,揭示了品牌AI资产在模型迭代中的衰减规律,建立了与CBBE遗忘曲线等价的动态解释机制。在CBBE与AIBE对比矩阵中新增“资产折旧机制”维度,完善了两种范式在动态视角下的系统性对照。
第三,顶层机制解释。以“认知寄生”与“标准寄生”两个核心概念,为AIBE金字塔L5顶层的形成提供了深层机制解释,并归纳出从L4到L5跃迁的“语义圈地—标准公开—无法绕开”三步路径,使L5从理想化的终局描绘转化为可分解、可追求的战略目标。
第四,底座工程化。将KNIT从宏观概念具象化为“品牌知识API化”的工程框架,明确了结构化事实库、可验证认证链、多模态元数据与语义映射表四大核心组件,为品牌将AIBE理论落地为可执行的技术方案提供了清晰指引。
9.2 研究局限
本文以理论建构为主,存在以下局限:
信任半衰期的具体时长受行业特性、模型迭代节奏、竞争强度等多重因素影响,本文仅提出了概念框架,尚需大量跨行业、跨模型的实证数据来校准参数。
认知寄生的成功案例在AI时代尚属早期,本文的案例演绎主要基于传统品牌认知(如沃尔沃与安全)的延伸推理,AI原生品牌的认知寄生路径有待更多纵向追踪研究验证。
跨模型环境下的资产稳定性系数测算方法有待进一步标准化,当前各主流AI模型的API开放程度与数据可获取性参差不齐,对AIBV动态追踪的规模化实施构成挑战。
9.3 未来研究议程
第一,多模态AIBE的非语义资产建构。随着Sora、GPT-4V等模型的成熟与普及,品牌的视觉标识(UI色调、Logo形态)、听觉标识(Jingle、提示音)乃至动态风格(视频剪辑风格、动画节奏)可能在AI生成的多模态内容中形成可识别的资产占位。未来的AIBE研究需要探索:非语义信息如何被AI编码为品牌特征?如何为多模态品牌资产建立“防伪”与“确权”体系?
第二,AIBE的商业价值归因模型。品牌AI资产的价值最终需要体现在商业回报上。未来研究需着力探索从“AI首提置顶率”到“实际市场转化率”(如产品页面访问量、试驾预约量、成交转化率)的漏斗折算系数。这一归因链条的打通,将使AIBE从营销学的理论概念升级为可纳入财务评估的品牌资产计量维度。
第三,跨文化AI认知疆域研究。品牌在不同语种、不同文化圈层的AI大模型中的AIBE表现可能存在系统性差异。对于走向全球的中国品牌,理解自身在ChatGPT英文版、Gemini多语种版、以及各区域主流AI平台上的认知资产分布,是制定精准出海战略的基础。
第四,AI幻觉的法律与声誉风险管理。当AI生成关于品牌的虚假或负面信息时,品牌面临声誉损害与法律救济的双重挑战。未来研究需探讨:品牌如何建立AI幻觉的主动监测与快速响应机制?在法律层面,AI平台对其生成内容中的品牌信息失真应承担怎样的责任?
人工智能不会让品牌建设变得更容易,它只是让“被信任”的资格变得前所未有地重要。在信息检索向AI代理转移的时代,品牌之间争夺的不再仅仅是消费者的注意力,更是AI认知体系中的信任顺位。AIBE理论及其深化框架,正是为这个“信任即流量”的新时代,提供一套可理解、可量化、可维护的品牌资产管理工具。未来的赢家,将是那些既懂得在人心上建立品牌、也懂得在模型上管理认知的双轨制品牌。
参考文献
[1] Statista. (2026). Number of generative AI users worldwide from 2022 to 2026. Statista Digital Economy Compass.
[2] 逄培.(2025)媒体型GEO:AI时代品牌信任资产构建新范式. 工作论文
[3] Choi, J., Lee, S., & Lee, J. (2020). When do people trust AI’s recommendations? The role of explanation and source credibility. Computers in Human Behavior, 112, 106470.
[4] Keller, K. L. (1993). Conceptualizing, measuring, and managing customer-based brand equity. Journal of Marketing, 57(1), 1-22.
[5] Aaker, D. A. (1991). Managing Brand Equity: Capitalizing on the Value of a Brand Name. New York: Free Press.
[6] Huang, M. H., & Rust, R. T. (2021). A strategic framework for artificial intelligence in marketing. Journal of the Academy of Marketing Science, 49(1), 30-50.
[7] Zucker, L. G. (1986). Production of trust: Institutional sources of economic structure, 1840–1920. Research in Organizational Behavior, 8, 53-111.
[8] Spence, M. (1973). Job market signaling. Quarterly Journal of Economics, 87(3), 355-374.
[9] Lewis, P., Perez, E., Piktus, A., et al. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
[10] Glikson, E., & Woolley, A. W. (2020). Human trust in artificial intelligence: Review of empirical research. Academy of Management Annals, 14(2), 627-660.
[11] 逄培, 等. (2025). 人本采信度实验报告:信源标注对AI推荐采纳意愿的影响. 未出版工作论文.
[12] Chaiken, S. (1980). Heuristic versus systematic information processing and the use of source versus message cues in persuasion. Journal of Personality and Social Psychology, 39(5), 752-766.
[13] Davis, F. D. (1989). Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Quarterly, 13(3), 319-340.
[14] Ebbinghaus, H. (1885). Memory: A Contribution to Experimental Psychology. New York: Dover.
[15] Collis, D. J., & Montgomery, C. A. (1995). Competing on resources: Strategy in the 1990s. Harvard Business Review, 73(4), 118-128.
[16] Schema.org. (2024). Organization, Product, and Review schema definitions. https://schema.org/.
[17] 中欧国际工商学院. (2026). AI时代品牌新蓝图:从消费者心智到模型认知的转型. 研究报告.
[18] 国家广告研究院. (2026). 生成式AI营销四位一体协同体系白皮书.
